这篇文章我已经酝酿颇久了,诱因是因为PingCAP团队为了推广他们的TiDB而在知乎专栏发了一篇文章《TiDB 增加 MySQL 内建函数》。受此文启发,我在网上搜索了一下PostgreSQL(以下略称”PG”)中定制内置函数(Built-in Function)相关的文章,果然没有搜到什么像样的中文文章。其实为PG添加内置函数并不难,可能是相对于hacking它的SQL引擎或者存储引擎等等话题而言,加一个内置函数的逼格实在是太Low吧。不过TiDB这个诞生还没多久的数据库产品都知道通过先利用内置函数这个话题来由简入深地吸引广大开发者为它贡献代码,PG作为一个诞生了已有20年的开源数据库老大哥却没有一篇像样文章,也难怪PG的普及率不高了。
以上就作为这篇分享的「意味づけ」吧…
什么时候需要去增加一个内置函数
其实在大多数情况下,鉴于PG提供了强大的SQL扩展能力,我们通常只需要掌握PG中User Define Function(略称:UDF)就够了。不过内置函数的特性与UDF还是有些不同的,因此在一些特定场景下,我们可能会不得不采用内置函数的方式去定制一些函数接口。
以下,我对比了一下内置函数和UDF的特性…
- 扩展灵活性
- 内置函数
不灵活。
对内置函数的增/删/改都必须通过修改并重编PostgreSQL源码实现。 - User Defined Function
很灵活。
通过CREATE FUNCTION以及DROP FUNCTION就可以实现UDF的增加与删除.且函数的具体实现可以通过多种语言(PL/pgsql,PL/python,PL/Perl等等)实现。
- 内置函数
- 可见性
- 内置函数
内置函数默认在所有实例的所有Database中都可见 - User Defined Function
由于UDF只是一个数据库对象。因此对于一个特定的UDF而言,一次CREATE FUNCTION只能使得它在该特定的Database中可见。若要在别的Database中也可见,需要在目标Database中也执行CREATE FUNCTION语句
- 内置函数
- 执行权限
- 内置函数
除非在内置函数的实现中做特定限制逻辑,否则内置函数默认对所有的数据库用户可执行 - User Defined Function
默认只有创建了的该UDF数据库用户拥有执行权限,对于其他用户,需要通过GRANT语句赋权
- 内置函数
对于大部分PG用户而言,他们对SQL级别的函数的期待通常都是与具体业务数据紧密相关的(其中的大部分都是希望去实现一些存储过程),因此对于这部分用户而言,UDF已经足够(PG中“存储过程”这个概念已被融入UDF)。通常,只有在以下这几种场景下,我们才需要去实现一个内置函数:
- 希望在SQL层面查询PG运行中的一些临时的内部状态(常见于做PG的商业发行版时为了为了满足一些特定需求)
- 希望在SQL层面可以对PG的内部执行加以一些控制(常见于做PG的商业发行版时为了满足一些特定需求)
- 纯粹只是想Hacking一下PG
增加内置函数的”三板斧”
其实为PG增添一个内置函数本身并不复杂,我总结下来也就三个步骤: 实现函数,声明函数 & 注册函数。下面我就用一个简单的例子来说明如何给PG增加一个内置函数。
1. 实现
仿照《PostgreSQL服务器编程》一书中的第8章实现一个最简单的函数:
输入两个INTEGER的参数,返回一个表示两数相加及其结果的等式(TEXT)
实现的代码如下:
Datum
add_str(PG_FUNCTION_ARGS) {
int arg_1, arg_2;
char buf[128] = {0x00};
char *result = NULL;
if (PG_ARGISNULL(0) || PG_ARGISNULL(1)) {
ereport(ERROR,
(errcode(ERRCODE_NULL_VALUE_NOT_ALLOWED),
errmsg("cannot specify NULL as the arguement.")));
}
arg_1 = PG_GETARG_INT32(0);
arg_2 = PG_GETARG_INT32(1);
snprintf(buf, 128, "%d + %d = %d", arg_1, arg_2, (arg_1 + arg_2));
result = pstrdup(buf);
PG_RETURN_TEXT_P(cstring_to_text(result));
}
这里需要注意的是,与用C语言编写UDF一样,编写的函数必须是一个fmgr-compatible的函数。即参数必须是PG_FUNCTION_ARGS, 返回值必须是Datum。这是由于PG中所有的SQL函数(含内置函数以及UDF)都被一个通用模块模块管理,该模块通过自己的一套机制去定位并执行SQL文中指定的SQL函数(SQL文中的函数调用机制,后面会另写博客分享)。
上述函数可以实现在PG中的任何一个代码文件中(当然也可以新建一个源文件定于)。不过需要注意的是,必须确保这个源文件包含了"funcapi.h"这个头文件。
此外,这个例子只是为了示意,所以做了一个最简单的逻辑。在实际开发中,对于SQL函数,通常有一类需求是希望函数返回一个结果集。对于返回结果集的SQL函数,PG中称之为SRF(Set Returning Functions). SRF的实现有一个固定范式,详细可以参见PG代码中的src/include/funcapi.h的注释,内有关于这个范式的详细说明。
2. 声明
PG中对于内置函数的声明有一个约定俗成的共通位置,即PG源码中的src/include/utils/builtin.h。通常都是在该头文件中将实现的内置函数声明为一个extern函数以确保其对其他源码文件可见。
不过,这也只是一个惯例而已,事实上,内置函数的声明位置并不一定限定与此。说白了,只要保证这个声明能让整个fmgr机制看到即可。
函数声明本身全无特别,在本例中,声明就只是下面简单的一句话:
extern Datum add_str(PG_FUNCTION_ARGS);
3. 注册
Last but not least. 对于内置函数而言,光有实现和声明是不够的。与其他的数据库对象相仿,内置函数的元信息必须写入PG的数据字典中。而且由于系统表是数据库实例生来就有的对象,并没有一个CREATE文能帮它把元信息写入数据字典,因此这个步骤必须在源码中事先完成。这就是所谓的注册。
与UDF一样,内置函数的元数据也是保存在系统表pg_proc中的。而pg_proc系统表在PG的数据库模板中初始状态下所具有的元数据元组是在src/include/catalog/pg_proc.h中注册的。每个元组的注册格式如下:
DATA(insert OID = 元组的唯一OID ( 内置函数名 属性1 属性2…… ));
DESCR(内置函数的描述信息(使用半角双引号引起来));
为pg_proc.h增加一个形如上文的元组时,有两个地方需要注意:
OID必须保证全局唯一
为
pg_proc.h增加元组时,必须分配一个9999以内的唯一OID(在写下一个OID之前,可以先全文搜索一下PG源码确保其唯一性)至于为什么一定要将这个OID选在9999以内,是因为PG源码的
src/include/access/transam.h对于Oid使用范围存在下述描述,且通过两个宏定义来限定: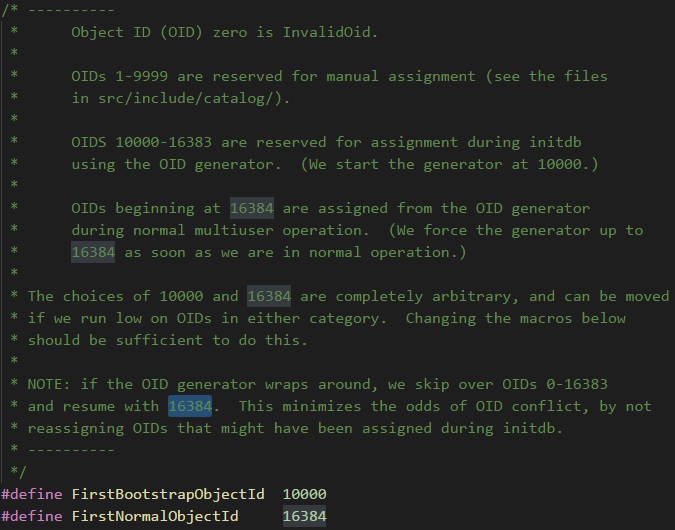
在本例中,通过甄选,将
add_str内置函数在pg_proc中元祖的OID选为5946元组各个字段属性的写法
pg_proc.h中内置函数的元数据的元组格式咋一看估计会让人懵掉。但实际上,这里的元组的各个属性(函数名已降的各字段)实际上对应的就是PostgreSQL手册中pg_proc系统表的各个字段。对照着这一章节的介绍以及参考pg_proc.h中已有的内置函数的元组,就可知道该如何为新的内置函数增添元组。以下是在手册基础上,对pg_proc的元组各字段数据的写法做的一些补充说明:
proisstrict 如果将此字段设置为
t, 只要通过SQL调用该函数时参数中有一个NULL,那么这个函数实际上不会被调用(即便函数实现中预备了对于NULL的处理)而是直接返回一个NULL。因此如果希望自己处理NULL参数,该字段不应为tproparallel 这个字段是 9.6 开始新加的字段。表示的是这个函数是否支持在并行查询的模式下并行执行。
prorettype 返回值类型。这里需要填入的是返回值类型所对应的OID。这些OID可以在
src/include/catalog/pg_type.h中寻找。但需要注意的是,这里填的OID不要使用宏定义,直接填OID的数字。另外,结果集对应的OID是2249。proargtypes和proallargtypes 这两个字段都需要以集合的形式写出参数类型OID集合。但写法上略有差别:
proargtypes的写法是
"OID1 OID2 ..."proallargtypes的写法是
{OID1 OID2 ...}。此外,如果返回值是一个结果集的话,填写此字段时,结果集中各个字段的类型也需要在proallargtypes中严格按照结果集字段的顺序一一声明。在这里,结果集字段与输出参数可以视作等同效果.如果函数不包括任何输出参数且返回值不是结果集的话,这个字段可以直接声明为_null_
另外,对于返回值是结果集的内置函数而言,也许要把结果集的每一个字段的信息反映在
proargmodes和proargnames这两个属性中。
由于本例的add_str()函数比较简单,因此它在pg_proc.h中对应的元组可写为
DATA(insert OID = 5946 ( add_str PGNSP PGUID 12 1 0 0 0 f f f f f f s s 2 0 25 "23 23" _null_ _null_ _null_ _null_ _null_ add_str _null_ _null_ _null_ ));
DESCR("add_str just for test");
到这里为止,向PG源码中增添新的内置函数的方法就已经介绍完毕了。但是在实践中,除了上述”三板斧”,还有一些坑最好也事先知道,以免在增添内置函数时走弯路.
踩过的那些坑
坑1. 内置函数的参数默认值
PG中的SQL函数的参数是可以定义默认值的,然而C语言编写的函数是没有办法为其参数指定默认值的。这个Gap还是必须得从PG自己的机制着手。好消息是pg_proc系统表中有一个字段叫做proargdefaults,它看上去似乎可以用于解决参数默认值的问题; 但坏消息是,这个字段接受的是一个以字符串形式表示的Express Tree,这几乎不是常人能通过人手能够写出来的。
幸运的是,PG社区的大牛Tome Lane在2009年的一封邮件中指出了为内置函数设置默认值的正确姿势: 不要尝试在pg_proc.h中通过元组的方式指定参数默认值——因为这种方式很”Ugly”——而是应该通过在src/backend/catalog/system_views.sql中通过SQL文定义一个带默认值参数的函数去覆盖用C语言编写的SQL函数。比如,他在邮件中提到的内置函数pg_start_backup():
CREATE OR REPLACE FUNCTION
pg_start_backup(label text, fast boolean DEFAULT false)
RETURNS text LANGUAGE internal STRICT AS 'start_backup';
换言之,可以先用C语言实现希望增加的内置函数的逻辑,再通过在system_views.sql中创建SQL函数接口。当然,这个C语言函数仍然得遵循上文所说fmgr-compatible范式.另外,由于system_views.sql中定义的函数不是预先写入数据库模板中的,而是在initdb创建实例的bootstrap过程中执行的,因此这样的函数的OID必然是在10000之后。
坑2. pg_proc.h中新元组的生效时机
按照前文所述的”三板斧”来编写一个内置函数时,如果所用的PG源码所展开的路径是第一次执行编译还好,如果在所展开的路径下先前已经编译过至少一次的情况下,这时就会出现一个神奇的现象:重编后的二进制中可以看到新加的内置函数但无论如何就是没法走到。
这是因为当我们给pg_proc.h中增加新的内置函数对应的元组时,以下三个文件会在源码编译过程中基于pg_proc.h的内容自动生成。
src/backend/catalog/postgres.bki src/backend/utils/fmgroids.h src/backend/utils/fmgrtab.c
这三个文件中生成的内容对于pg_proc系统表中的初始化元组起重要作用。但是这三个文件只会在第一次编译时生成且并不会在make clean时被清理掉。因此,如果是在一个已经执行过至少一次编译的源码环境中增加新的内置函数时,若要”三板斧”的最后一斧生效,必须在编译前执行下述命令:
$make maintainer-clean
当然,这样一来原本生成的所有Makefile也将被清理掉,之后要编译这份代码的话,必须从./configure重新开始。
创建内置函数时最好知道的PG内部API
用C语言为PG做扩展有一些通用的内部接口可供使用,这些接口也不限于内置函数。所以在我所知道的范围内列出一些内部接口,以作备忘:
- SPI系列函数 可以用于在内部执行SQL等等
- 直接操作元组(Tuple)相关API
CreateTemplateTupleDesc()TupleDescInitEntry()BlessTupleDesc()heap_from_tuple()
- 用于查询执行时当前会话状态判断的实用函数
superuser()判断当前用户是否是DB的超级用户IsTransaction()判断当前语句是否在一个显式事务块中IsInParallelMode()判断当前是否在并行执行模式中- 全局变量
XactReadOnly判断当前会话是否是只读模式
结语
以上就是给PG添加内置函数的方法的一个小结,也是我最近一段时间一直在折腾PG的SQL函数所做的一点积累, 希望能够为有类似需求的人提供一些帮助。
