由于手头当前的工作是基于PostgreSQL(以下简称PG)做二次开发,因此目前对PG的源码也或多或少地读了一些,因此便想到了在博客里分享一些关于阅读PG源码所获得的KnowHow。
在国内的PG技术圈内,提到PG源码解读自然首推武汉大学的两位彭老师所著的《PostgreSQL数据库内核分析》。不过这本书的着眼点是对PG源码的整体架构,以及SQL引擎,存储系统,事务处理等等这些实现机制&算法的介绍,而我则主要想分享一些PG代码中的一些有意思的小细节/小功能。虽然只是PG那几百万行源码中的沧海一粟,不过从这些小细节中解读程序设计的匠心也是颇有意思的。
第一篇就从PG中无处不在的OID开始吧
什么是OID
关于PG中OID(Object Identifier)的概念在PostgreSQL官方手册有比较详细的介绍。简短洁说就是PostgreSQL内部用于标识数据库对象(即通常意义上的数据表,视图,存储过程之类)的一个长度为4字节的标识符。它是PostgreSQL大部分系统表的主键。PostgreSQL一个为人称道的特点就是其提供了超强的扩展性,用户甚至可以对PostgreSQL的数据类型, 运算符, 存储过程语言进行扩展。而支撑其扩展性的基盘就是系统表和OID
OID在系统表中通常是作为隐藏列存在的,它是以整个PostgreSQL数据库实例(Database Cluster)的范围内统一分配。在单个系统表内保存的OID一定可以保证OID的唯一性,但是OID不能保证跨系统表之间的唯一性 —— 也就是说,可以假定“两个存储过程对象的OID不可能相同”; 但是绝不能假设“一个表对象的OID肯定不等于一个存储过程对象的OID”(尽管在大部分情况下确实不相等)。此外,对于用户定义的数据表,PostgreSQL默认不会为其中的元组分配OID,除非建表时显式指定(其实PostgreSQL并不鼓励用户建表时指定包含OID, 并且不赞成用户的业务逻辑依赖于普通数据表的OID)。
由于OID是系统表的隐藏列,因此查看系统表中数据库对象的OID时,必须在SELECT语句中显式指定。下图显示了如何查看一个新创建的Database对象的OID:
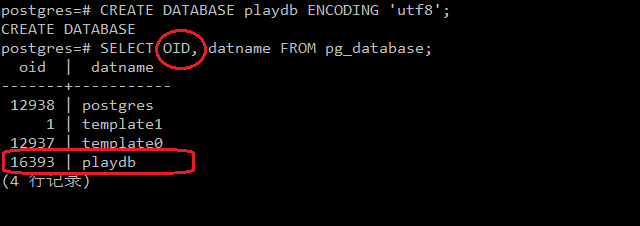
但是,对于一个使用CREATE TABLE创建的普通表,PG默认不会为表中的元组保存OID, 自然执行SELECT语句时也无法查到oid这一列。比如下图所示:
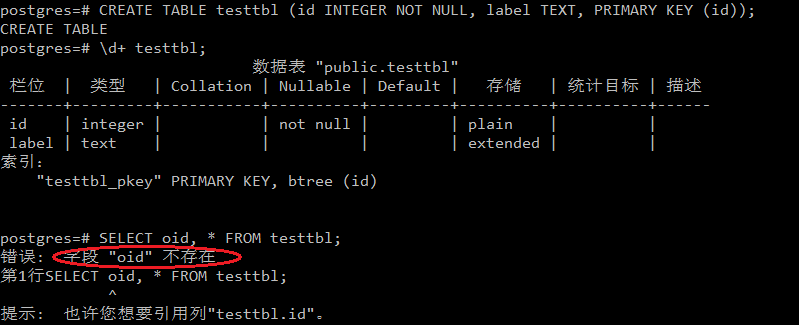
如果希望在向表中插入数据时让PG为每一个元组生成OID,则需要在CREATE TABLE时显式地加上WITH OIDS这个属性。如下所示:
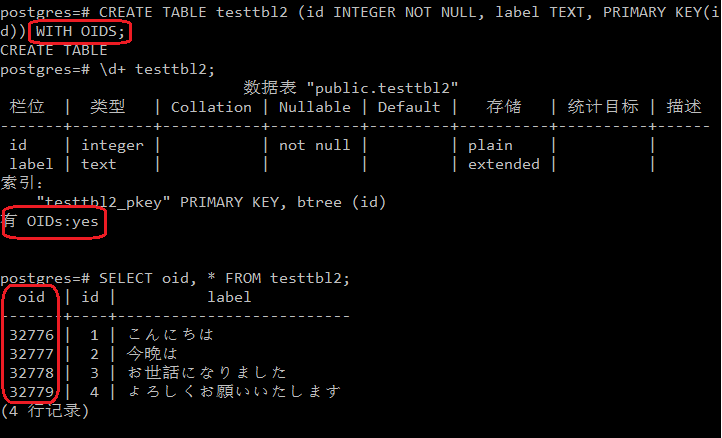
需要注意的是,尽管默认情况下PG不会为用户数据表的元组分配OID,但是对于用户创建的每一张表,PG还是会生成一个OID在系统表进行标识
OID机制的实现
接下来将从以下几个方面聊一聊PG中关于OID机制的实现
- OID的保存与共享
- OID的分配机制
- OID的持久化
OID的保存与共享
众所周知PG是一个多进程架构的数据库,每个用户会话对应了一个postgres进程, 由于受用户的DDL语句/DML语句操作,每一个postgres进程都有可能同时要求分配新的OID; 与此同时实例内部的一些常驻后台进程的动作也可能要求分配新的OID。因此若要实现整个实例范围内的OID统一管理,那么通常首选方案就是共享内存, 事实上PG也是这么做的:
首先,PG中设计了一个VariableCacheData结构体来存放OID相关的数据:
/* include/access/transam.h */
typedef struct VariableCacheData
{
Oid nextOid; /* 保存了下一个要分配的OID */
uint32 oidCount; /* 剩余可用的OID个数 */
TransactionId nextXid;
TransactionId oldestXid;
TransactionId xidVacLimit;
TransactionId xidWarnLimit;
TransactionId xidStopLimit;
TransactionId xidWrapLimit;
Oid oldestXidDB;
TransactionId oldestCommitTsXid;
TransactionId newestCommitTsXid;
TransactionId latestCompletedXid;
} VariableCacheData;
在整个数据库实例的运行期间,只会在实例启动时(也就是Postmaster进程启动时)在共享内存内创建一个VariableCacheData结构体实例,同时Postmaster进程会将自己的VariableCache类型(本质上就是VariableCacheData指针)的全局变量ShmemVariableCache赋值为共享内存中VariableCacheData结构体的地址。由于在linux上通过fork()创建子进程时子进程会继承父进程的所有资源——包括全局变量。因此在实例运行过程中,Postmaster的子进程(含所有postgres进程以及其余的常驻后台进程)也就都共享了这个结构体的地址。
全局变量ShmemVariableCache的定义以及初始化的代码如下所示:
- 变量定义
/* backend/access/transam/varsup.c */
...(中略)...
VariableCache ShmemVariableCache = NULL;
...(下略)...
- 初始化
/* backend/storage/ipc/shmem.c */
void
InitShmemAllocation(void)
{
~(中略)~
ShmemVariableCache = (VariableCache)
ShmemAlloc(sizeof(*ShmemVariableCache));
memset(ShmemVariableCache, 0, sizeof(*ShmemVariableCache));
}
需要注意的是Windows上的进程模型与Linux不同,Windows上并没有像fork()这样能使子进程天生继承父进程资源的机制。因此PG在Windows上实现Postmaster进程向子进程传递全局变量ShmemVariableCache时稍微绕了一下,将相关的地址dump到一个临时文件”pgsql_tmp”中,然后在调用CreateProcess()创建子进程时将文件路径传入后再由子进程从文件中将地址恢复出来。这个过程就不在此处赘述了。
OID的生成机制
当一条元组被INSERT到表中的时候(也包括语法层面的UPDATE语句,因为PG中的UPDATE本质上是将更新前的旧元组标记为无效并新增元组)。如果这是一张系统表,或是一张在创建时加了WITH OIDS的用户数据表,那么在写入元组的时候,PG就会申请生成一个新的OID,并写到新元祖的OID字段中,这时就涉及到了OID的生成。
OID的生成逻辑其实非常简单,其核心算法就是”把在保存共享内存的VariableCacheData结构体中当前的nextoid分配出去,之后让nextoid自增一,同时让oidcount减一”。当然,考虑到多个会话的并发,所以在执行上述算法的时候,会加上一把排他锁。
上述核心算法的代码如下所示:
/* backend/access/transam/varsup.c */
Oid
GetNewObjectId(void)
{
Oid result;
if (RecoveryInProgress())
elog(ERROR, "cannot assign OIDs during recovery");
LWLockAcquire(OidGenLock, LW_EXCLUSIVE);
if (ShmemVariableCache->nextOid < ((Oid) FirstNormalObjectId))
{
if (IsPostmasterEnvironment)
{
ShmemVariableCache->nextOid = FirstNormalObjectId;
ShmemVariableCache->oidCount = 0;
}
else
{
if (ShmemVariableCache->nextOid < ((Oid) FirstBootstrapObjectId))
{
ShmemVariableCache->nextOid = FirstNormalObjectId;
ShmemVariableCache->oidCount = 0;
}
}
}
if (ShmemVariableCache->oidCount == 0)
{
XLogPutNextOid(ShmemVariableCache->nextOid + VAR_OID_PREFETCH);
ShmemVariableCache->oidCount = VAR_OID_PREFETCH;
}
result = ShmemVariableCache->nextOid;
(ShmemVariableCache->nextOid)++;
(ShmemVariableCache->oidCount)--;
LWLockRelease(OidGenLock);
return result;
}
这个简单的分配算法中有几个细节稍加说明一下:
一开始的对
RecoveryInProgress()的调用,是判断当前实例是否处于恢复状态。我个人认为与其说它是在防护实例的恢复状态下不应存在的写操作,更不如说它是对Hot standby节点禁写原则的又一层防护,毕竟Hot standby节点一直是运行于恢复态的。也就是说,Hot standby节点上的OID只能通过应用xlog来得到。在之前的博文如何为PostgreSQL创建一个内置函数?我曾提到过16384这个OID,事实上这也正是PG实例的Bootstrap过程结束后第一个留给用户的OID。因此,当OID递增耗尽回卷时,回卷后的第一个OID不是0,而是16384(也就是上述代码中的
FirstNormalObjectId)。这样可以确保PG实例内的所有内置数据库对象的OID是绝对唯一的。从上述代码可知,OID在每分配8192(即代码中的宏
VAR_OID_PREFETCH)个之后便会向xlog中记一条关于下一个OID分配区间的最大值。这个设计的意图会在下一章节介绍,此处暂时略过。
但是,由于OID只有四个字节,因此可以预见到它会有溢出的时刻,这时就会产生上文的所说的回卷逻辑。当OID回卷时,如何保证OID的相对唯一性(这里的“唯一性”在“什么是OID”这一章中有说明)呢?PG中实际上是在上述GetNewObjectId()之外又封装了一个GetNewOid()接口供PG代码使用,而在这个接口实现中,PG通过OID字段的索引实现了OID在一张表内的唯一性:
/* backend/catalog/catalog.c */
Oid
GetNewOid(Relation relation)
{
Oid oidIndex;
Assert(relation->rd_rel->relhasoids);
if (IsBootstrapProcessingMode())
return GetNewObjectId();
oidIndex = RelationGetOidIndex(relation);
if (!OidIsValid(oidIndex))
{
if (IsSystemRelation(relation))
elog(WARNING, "generating possibly-non-unique OID for \"%s\"",
RelationGetRelationName(relation));
return GetNewObjectId();
}
return GetNewOidWithIndex(relation, oidIndex, ObjectIdAttributeNumber);
}
Oid
GetNewOidWithIndex(Relation relation, Oid indexId, AttrNumber oidcolumn)
{
Oid newOid;
SnapshotData SnapshotDirty;
SysScanDesc scan;
ScanKeyData key;
bool collides;
Assert(!IsBinaryUpgrade || RelationGetRelid(relation) != TypeRelationId);
InitDirtySnapshot(SnapshotDirty);
do
{
CHECK_FOR_INTERRUPTS();
newOid = GetNewObjectId();
ScanKeyInit(&key, oidcolumn, BTEqualStrategyNumber, F_OIDEQ,
ObjectIdGetDatum(newOid));
scan = systable_beginscan(relation, indexId, true, &SnapshotDirty, 1, &key);
collides = HeapTupleIsValid(systable_getnext(scan));
systable_endscan(scan);
} while (collides);
return newOid;
}
其实它的思路也很简单: 如果这张表上没有基于OID字段的索引(理论上这种情况不会发生在系统表上,只会在用户的数据表上),那么就直接调用上述核心算法的GetNewObjectId()直接生成一个OID; 如果表上存在基于OID字段的索引,那么就反复尝试调用GetNewObjectId()直到生成了一个这张表中未曾出现过的OID.此时生成的OID尽管可以保证在目标表中唯一,但很有可能它已经在别的表中也已经被使用了。这就是为什么在第一章中会说“在单个系统表内保存的OID一定可以保证唯一性,但是OID不能保证跨系统表之间的唯一性”
OID的持久化
搞清楚了OID的生成机制,很自然地就会产生一个想法: 既然每生成一个OID都会加锁,那么在上述的OID唯一性确保逻辑中如果尝试生成OID的次数过多,那就肯定会对并发的性能造成较大的伤害。但OID又是一个保存在共享内存中的数据,假设每次实例正常停机/重启或者异常Crash后恢复,OID就又要从初始的16384开始重新递增,结合上述生成逻辑中确保表内唯一性的试错循环,这对性能将是一个灾难!
还好,PG的开发者们也想到了这一层, 而上述悲惨情况之所以不会发生的原因是因为PG中对于共享内存中的newoid进行了持久化以确保实例重启后或者恢复后,还能够接着之前的newoid生成,而不是从头再来一遍。
持久化的时机
PG对于newoid的持久化有两处:
时机1: 上文的OID核心生成算法中所述——每分配完8192个OID就向xlog中插入一条记录,将下一个8192分配区间的最大值记录在xlog中。
这里需要注意两点:
PG并不是每生成一个OID就向xlog中记录一次。理由是虽然这样很保险,但是记录xlog(就算只是写缓冲区)也是会对性能带来负面影响。
写在xlog中的不是当前已分配区间的最大OID,而是下一个分配区间的最大OID。这样一来它可以保证在这个分配区间结束之前,所有已落入磁盘上的元组中,没有一个OID会大于这个写入xlog记录的OID(OID发生回卷除外……)。这个设计意图在接下来介绍oid的恢复机制时会解说其用意。
时机2: 生成Checkpoint时, 按下述逻辑将oid数据写入PG实例控制文件的检查点信息中.
void CreateCheckPoint(int flags) { ~(前略)~ CheckPoint checkPoint; MemSet(&checkPoint, 0, sizeof(checkPoint)); checkPoint.time = (pg_time_t) time(NULL); ~(中略)~ LWLockAcquire(OidGenLock, LW_SHARED); checkPoint.nextOid = ShmemVariableCache->nextOid; if (!shutdown) checkPoint.nextOid += ShmemVariableCache->oidCount; LWLockRelease(OidGenLock); ~(后略)~ }有意思的是,记录在Checkpoint时会根据Checkpoint的种类来执行不一样的记录行为:
如果是SHUTDOWN检查点,则记录真实的下一个待分配的OID
如果不是SHUTDOWN检查点,则记录的其实和记录在xlog中的类似:当前分配区间的最大值。理由也是相仿的: 确保当前时间点已落入磁盘的元组中的已生成OID没有大于记录在checkpoint信息中的OID。
两个持久化位置几乎殊途同归,持久化OID的策略几乎相同,这应该不是巧合:)
恢复机制
接下来从PG的恢复机制来揭晓上述持久化的残留疑问。
PG从xlog恢复数据时一定是从最近的Checkpoint开始恢复,因为已实施的Checkpoint可以保证到这个Checkpoint为止的数据变更都已经落盘,且已利用xlog进行了一致性确认。所以PG只需要从这个最近的Checkpoint之后的xlog开始恢复即可。 所以,我们可以将全局的VariableCacheData结构体中的newOid字段的恢复分成以下几种情况:
最近的Checkpoint之后没有记录NewOid的xlog记录
这说明,实例Crash掉的时间点到最近的Checkpoint之间的时间间隔内,Oid的生成还在同一个8192的分配区间内。这时,即便Checkpoint之后还有一些新的数据写入,但是由于Checkpoint信息中持久化的是当前OID分配区间的最大值,因此可以确保Checkpoint之后分配的OID没有一个能够超过被持久化的那个OID。因此将全局的
VariableCacheData结构体中的newOid字段恢复成当前分配期间的最大值,后续再生成新的OID也不用经历生成逻辑中确保表内唯一性的试错循环。最近的Checkpoint之后存在一条或多条记录NewOid的xlog记录
这说明,实例Crash掉的时间点到最近的Checkpoint之间,OID的生成已经跨越了多个8192的分配区间。不过,由于xlog中记录NewOid时记录的都是每一个OID分配区间的最大值。与上一个情况相似,在逐个应用每一条记录NewOid的xlog日志记录后,最终会将将全局的
VariableCacheData结构体中的newOid字段恢复成最后一个被使用的OID分配区间的最大值,仍然可以保证后续再生成新的OID也不用经历生成逻辑中确保表内唯一性的试错循环。当然,这两种情况都是建立在OID尚未发生回卷的前提下才有实际意义。如果已经发生了回卷,
newOid恢复的其实是一个较小的值,那么试错循环应该就不可避免了。最后一种情况,最近的一个Checkpoint是SHUTDOWN检查点.
这就意味着实例是被正常关闭重启的, 那么自然这个Checkpoint之后当然不会有任何新的xlog,也自然不会有任何磁盘上的数据更新。因此此时恢复的就是关机Checkpoint时真实的下一个待分配的OID。实例重启后从这个OID开始继续递增即可。
由此可见,为了让PG实例启动/恢复后生成新的OID时能够尽可能减少保证唯一性的试错循环带来的负面影响。PG基于已有的恢复机制设计了一套比较合理又巧妙的持久化机制。
上述恢复逻辑写在了backend/access/transam/xlog.c的
xlog_redo()函数和StartupXlog()函数中,由于代码较多便不再贴出。
关于OID的一些思考
关于OID本身的规格以及机制的介绍,基本上就到此结束了。OID的存在,实际上为PG内部的数据库对象实现了一个统一的抽象接口,进而PG可以实现其引以自豪的强大扩展能力。不过,站在”事后诸葛亮”的角度,我们还是可以看出OID设计中的一些遗憾。
最大的遗憾恐怕是把OID设计得有点短了: 4个字节对于今天的大数据时代而言,很容易就耗尽了。而且在上文中也说过,一旦4个字节单调递增结束进入回卷阶段,那么将有可能会给PG的性能带来较大的负面影响。
其实从上述OID的实现代码我们可以合理推测: 一开始的设计初衷中,OID肯定是希望被用来对PG中的所有数据库对象(包括用户数据表中的元组)进行唯一性标识的。佐证有两点:一来是OID的生成机制是简单递增; 二来是到PG 8.0为止的手册里,用户CREATE TABLE创建的数据表的默认行为是会给所有插入元组附上OID。当然,站在今天这个时间点上,唯一标识实例中所有数据库对象的重任肯定是没法儿交给OID来完成,因此OID就变成了系统表的专属“玩物”了。
这个遗憾,恐怕可以比肩当年比尔盖茨的“内存有640KB就够了”的预言以及即将枯竭的IPv4地址资源。
最后,再发散性地想一想: OID本身就是为了实现一个自增的唯一性ID。如果扩展到分布式系统架构下,PG的OID实现是否也可以套用呢? 答案是肯定的,只需要把上述OID的实现机制中的两部分替换掉,我们就可以用完全相同的逻辑来实现一个适用于分布式架构下的高可用自增唯一性ID的生成服务。而那需要替换掉的两部分分别是:
- 将共享内存替换为一个高可用的内存数据库(比如Redis)
- 将单机上的磁盘替换为一个高可用的持久化存储组件(比如一个DBMS)
昨天看到的这篇文章基于 Redis 的序列号服务的设计则基本上验证了我的上述想法。难怪陈皓在不同场合都一直在劝诫程序员:“基础上的东西的变化少,基础上的东西一通百通”。果然如是!
